Statistics analysis results graph
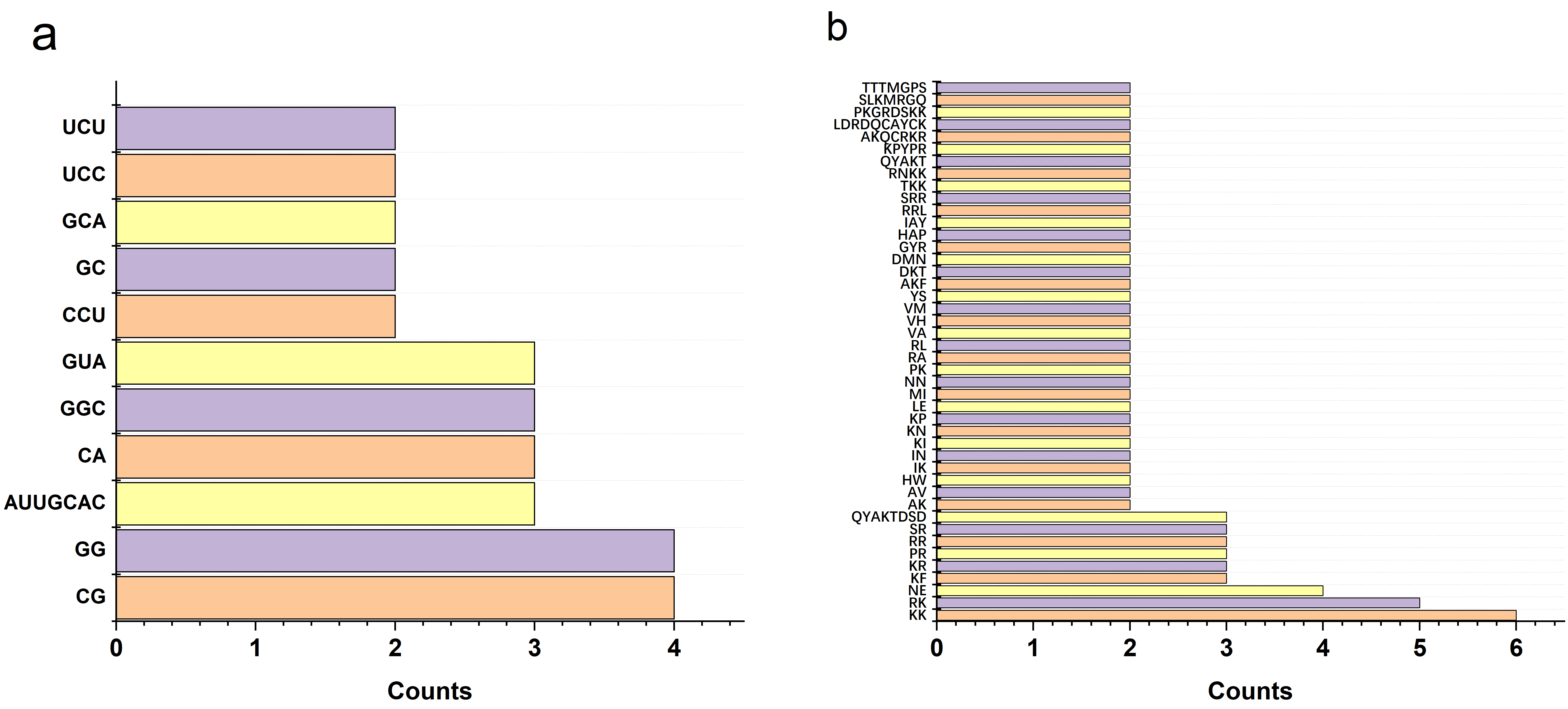
Figure 1. (a) and (b) show the statistical results of the RNA/protein binding fragments. The ordinate represents different binding frgraments, and the abscissa represents the number of occurrences of the corresponding binding fragments.
Figure 2. (a) is the RNA nucleotide distributions which locating at the RNA-protein interface. The distributions of G (31.3%) and C (26.4%) are significantly higher than A (21.5%) and U (20.8%). (b) is the RNA nucleotide backbone (phosphate and sugar) and side-chain (base) distributions interacting with proteins.
Figure 3. The secondary structure distributions in RNA-protein interaction interface.The abscissa represents the proportion of RNA secondary structure in interaction interface, and the ordinate represents the secondary structure of protein. The protein loop prefers to bind to RNA stem region.
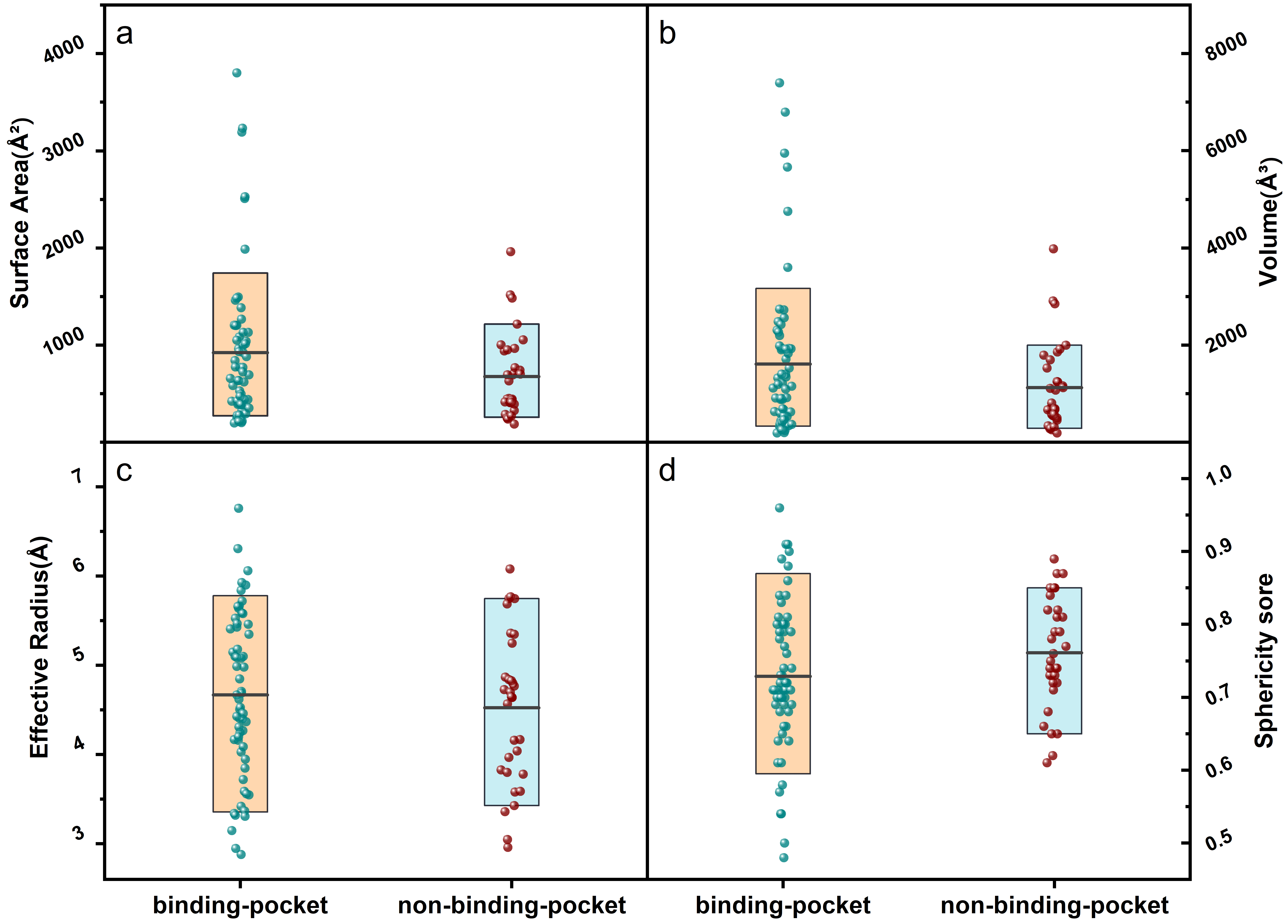
Figure 4. The geometric information distribution of surface area (a), volume (b), effective radius (c), and spherical similarity scores (d) for binding-pocket and non-binding-pocket of RNA. Boxes in (a), (b), (c) and (d) represent the 80% core distribution (ranging from 10th to 90th percentile), the black line on the box represents the average value.
Figure 5 (a) The average frequency of the amino acid located at the RNA-protein interface. (b) The average contribution of the amino acid interacting with nucleotides. (c) The average contribution of the amino acids interacting with RNA backbone (phosphate and sugar) and bases. Boxes in (a), (b), and (c) represent the 90% core distribution (ranging from 5th to 95th percentile). The black lines on the box represent the average values.